Re-inventing the Maintenance Process
|
| Plant Maintenance Resource Center
Re-inventing the Maintenance Process
| |
|
|
|
|
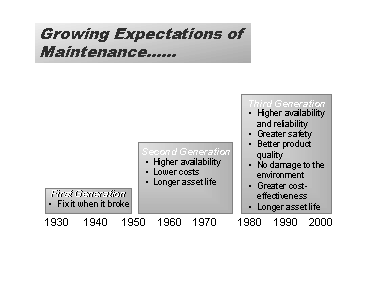
RE-INVENTING THE MAINTENANCE PROCESSTowards Zero DowntimeA Conference Paper presented to the Queensland Maintenance ConferenceBy Sandy Dunn May 1998 INTRODUCTIONThe field of Maintenance Management is changing as rapidly as any other field of management (with the possible exception of Information Systems Management). Moubray (1997) outlines the changes as being in three main areas:
And considers that Maintenance Management has passed through three "generations" as outlined below.
Fundamental amongst the differences between Second Generation and Third Generation Maintenance are:
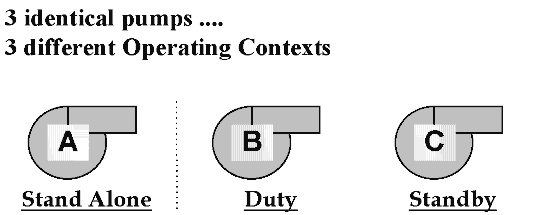
This paper outlines the experiences of those organisations that are well advanced in the implementation of Third Generation Maintenance principles, and puts forward the a view of what the Fourth Generation of Maintenance may be. But first, let's examine the goals of zero downtime or zero in-service breakdowns - is this achievable, or, indeed, desirable? IS THE OBJECTIVE OF MAINTENANCE TO PREVENT ALL FAILURES?Many organisations (particularly those who have been converted to the "religion" of Total Productive Maintenance (TPM) have stated one of their maintenance goals as being the achievement of zero breakdowns - zero in-service failures. Putting to one side, for the moment, the question of whether, in practice, this is actually achievable, let's first address the question of whether this is desirable. Consider, for example, a fixed plant situation where there are three brand new, identical pumps all pumping the same quantity of the same fluid against the same head, as illustrated below.
And let's say that we wish to establish a preventive maintenance program for these pumps with the aim of achieving zero in-service breakdowns. What type of maintenance strategy might we adopt? The chances are that the maintenance program will be one which includes tasks such as:
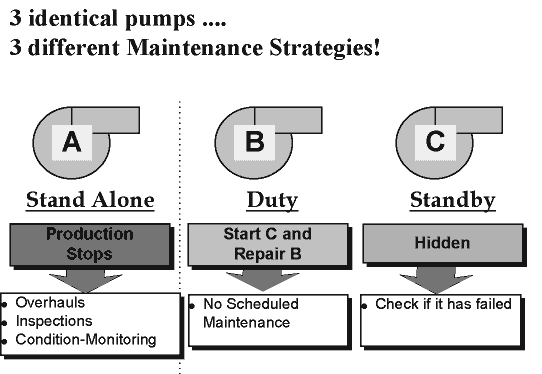
for all three pumps. But let's take a closer look at the situation. Let's say, for example, that the pumps are still are three brand new, identical pumps all pumping the same quantity of the same fluid against the same head, but that they are situated in two different areas of the plant. Pump A is a stand-alone pump, while Pumps B and C operate as a duty/stand-by pair - Pump B normally operates on its own, and we only run Pump C if Pump B is not working for any reason.
In this instances, if we consider the consequences of failure in each of the three cases, we will end up with three quite different maintenance programs for each of the three pumps, as illustrated below.
There are two key points arising from this example. First, when developing the maintenance program for Pump B, was the objective to eliminate all in-service failures of this pump? Clearly not, as the decision has been taken (appropriately) to run this pump to failure. Similarly, will the maintenance program chosen for Pump C prevent its in-service failure? Again, the answer is no - the best it will do is help us to determine whether it has failed, so that we can take appropriate corrective action. So if the objective of maintenance in each of these cases was not to prevent the failure of the equipment item, what was the objective of maintenance? The objective of maintenance in all three of the above cases - and this is a fundamental paradigm shift from traditional thinking about maintenance that is brought on by the adoption of Third Generation, Reliability Centred Maintenance principles - is not to avoid the failure of the equipment, but to avoid the consequences of the failure in each case. In practice the consequences of failure in all cases can be categorised in the following four categories:
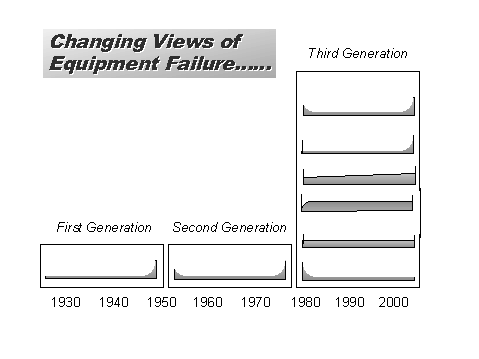
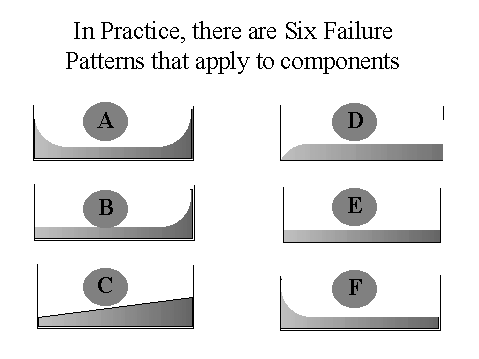
Hence the consequences of failure have a large bearing on the appropriate maintenance program to adopt for any item of equipment (and this in turn is affected by the operating context within which the equipment is asked to operate). The second key point from this example is that if you had established the maintenance program for Pumps B & C with the objective of eliminating in-service breakdowns of this equipment, then you would have been indulging in significant over-maintenance of those equipment items. Clearly, performing routine overhauls, condition-monitoring and inspections is significantly more expensive than repairing the item only after it has failed - and yet the additional expenditure on these activities yields no additional operational benefit. So to sum up, the objective of maintenance is not to eliminate all failures, but it is to eliminate the consequences of failure. BUT WHAT ABOUT FAILURES WITH SAFETY CONSEQUENCES?Ah yes, I hear you say, but what about those failures that have safety consequences, where a failure could possibly result in serious injury or death - surely in these circumstances the objective of maintenance is to eliminate these failures. Well let's examine this a bit further.Research in the airline industry in the 1960's and 1970's, which led to the development of Reliability Centred Maintenance principles, showed that there are 6 possible failure patterns that can apply to components. These are illustrated below.
In these graphs, the vertical axis is the conditional probability of failure, and the horizontal axis is time. There is insufficient time to go into the reasons for these six patterns existing, or the full implications of these patterns for maintenance strategy, but suffice it to say that Patterns A, B and C tend to apply to simple components, or systems with a single dominant failure mode (for example, wear liners, slurry pump impellers etc.). On the other hand, patterns D, E and F tend to apply to more complex systems, such as hydraulic, electronic and pneumatic control systems. Furthermore, the research in the aviation industry showed that, for large civil aviation aircraft, around 89% of components failed with failure patterns D, E or F, while only 11% failed with failure patterns A, B or C. Now let's consider the on-board computer on a fly-by-wire aircraft, such as the Airbus 320. If the system fails, the most likely effect is that the aircraft will become uncontrollable, and crash, potentially killing all on board . What failure pattern is likely to apply to this system? It is most likely to be either failure pattern E or F, but for simplicity's sake, let's assume that it complies with failure pattern E. What are the implications of this for maintenance? Is failure of the on-board computer likely to be predictable? It is made up of a lot of solid state electronic devices, can you predict when these will fail? Anyone with experience of electronic equipment (such as your own microwave ovens, video recorders etc.) will realise that these devices give no warning before they fail, and the failures are, therefore, totally unpredictable. Would a routine change-out of the on-board computer eliminate or reduce the probability of failure? Examining failure Pattern E, we see that if we were to replace the on-board computer, then the new computer we install is just as likely to fail as the old computer we removed. Worse, if the computer complies with failure pattern F, performing routine replacement of the on-board computer actually makes it less reliable, as we are introducing "burn-in" type failures to what was previously a stable system. So where does that leave us? The conclusion is that, in this instance, no amount of maintenance will eliminate failure of the on-board computer, whether based on Reliability Based Maintenance principles, or not. Think about that the next time you are flying on an Airbus 320! If this is the case, and the elimination of failures (even with safety consequences) is unachievable, can this be a realistic objective of maintenance? RCM AND INHERENT RELIABILITYIt can be seen, therefore, that the best that RCM can do is improve the reliability of a system to its inherent reliability, which is a function of system design and its operating context.Let's go back to the example of the Airbus 320 on-board computer, because things aren't quite as bad as they may at first seem. First, the on-board computer is designed with a high level of reliability. Let's say that the probability of it failing in any given period is 1 in 1000.
However, if the system was designed with a complete backup system in parallel, that is capable of taking over if the primary system failed, then the reliability of the system would be 1 in 1,000,000.
In fact, the Airbus 320 has four independent levels of backup, so you can see that the overall system is very reliable indeed. However, even with four levels of backup, the probability of a failure is not zero (even though it may be very close to it). The issue in design (as in maintenance), therefore, is not attempting to eliminate failures altogether, but in deciding how close to zero probability of failure is ultimately tolerable. It should be noted that current Third Generation Maintenance approaches, such as TPM and RCM, do not provide formal tools for assessing the most appropriate design to improve the inherent reliability of the system. However, RCM will highlight those areas where the inherent design of the asset yields probabilities of failure that are unacceptable, and provide some guidance and motivation for improving those assets. In practice, this has resulted in appropriate engineering design attention being given to assets where unreliability was previously perceived to be a maintenance issue. TOWARDS THE FOURTH GENERATION OF MAINTENANCESo if RCM has these limitations, why is it rapidly being adopted as a method of choice for determining equipment maintenance strategies by almost every major industry world-wide?First, let's be clear that the characteristics of RCM which we have discussed so far are not limitations, but features. It is precisely because RCM recognises that it is not desirable, nor in many instances achievable, to eliminate all failures that it is achieving significant results in improving equipment performance, while simultaneously reducing maintenance costs across a wide variety of equipment. Consider the following results that have been documented in various case-studies:
Clearly RCM is a valuable tool which can yield substantial improvements in equipment performance. But, as we saw earlier, the gains to be made by maintenance alone are limited to those that are possible within the limitations of the design of the equipment being maintained, and its operating context. Leading edge maintenance organisations (such as those in the aviation industry) have found that, after they have successfully implemented Third Generation maintenance techniques, such as RCM, the focus shifts away from Maintenance and there is increased pressure on equipment designers to ensure that systems are designed to achieve the desired levels of reliability and availability. Further, we saw that one of the key design decisions that needed to be made was the desired level of reliability and availability. In the case of failure modes that have potential safety or environmental consequences, this requires formal decisions to be made regarding the level of risk that can be tolerated for those failure modes. As you can imagine, this is a highly emotive issue, and one that most senior managers would prefer to avoid, despite the engineering logic behind it! Indeed the Federal Aviation Administration in the US has recently has come under some political and public pressure as a result of its announcement to drop its aim of achieving zero crashes. It should be stated, however, that while the aim of zero crashes was one that was acceptable to the general public, the industry itself has never striven for zero crashes, simply because it is unachievable, and unhelpful in making effective equipment design decisions. Nevertheless, design assumptions and decisions are currently being made in all organisations (such as those made in the design of the on-board computer system on the Airbus 320) that directly influence the level of risk that will be experienced by the organisation, but these decisions are generally being made in an ad-hoc way, at low levels within the organisation, and without a coordinated approach for ensuring that the total risk to the organisation is tolerable. Furthermore, these decisions are being made without reference to the equipment maintenance strategies that may need to be put in place in order to permit the equipment to continue to operate with the desired level of overall risk to the organisation. So Fourth Generation Maintenance organisations are starting to move towards a more holistic view of their assets. This Fourth Generation of Maintenance will build on the previous three generations, but will be distinguished by three main features:
There are a number of tools that currently exist that address the first two areas, but none of them successfully integrates Maintenance into the equation, and are much less effective as a result. In the area of risk assessment, for example, there are tools such as Probabilistic Safety Assessment, Probabilistic Risk Assessment, Quantified Risk Assessment, and others. These tools are all "top down" approaches, which involve setting risk targets at the highest level of an organisation, and then "cascade" these targets down through lower levels of the organisation, down to equipment areas, and potentially, down to failure mode level. All of these tools, however, ignore, at a micro level, the findings of Nolan & Heap and the principles of Reliability Centred Maintenance. As a result, there is no "bottom up" check that the targets that have been set are actually achievable. In addition, human factors are generally ignored, or simplistic assumptions made about the probability of failure caused by human error. The net result of these weaknesses is, without fail, a mistaken belief on the part of senior managers that their plant or equipment is, in fact, safer than it really is. In the area of Equipment design, there are tools such as Design for Maintainability, Value Engineering, Hazop, and others, that again, are not integrated with maintenance decisions. Take, for instance, the real-life example of a large stamping press that was designed for use in pressing body panels in the automotive industry. RCM analysis indicated that a protective device (to automatically shutdown the press if a bearing failure on a high speed rotating shaft was imminent) should be periodically tested. Unfortunately, the only way that access could be gained to the device to test it was by cutting the machine apart with an oxy-acetylene gun! Hazop tends to recommend redesign of the equipment whenever an unacceptable hazard is identified, when, in fact, a maintenance task may exist which is far more cost effective in dealing with the hazard. RCM's first preference is to recommend a maintenance task (if one exists), which is the appropriate decision, in the short term, but RCM does not provide any formal tools for considering alternative longer term redesign solutions, or for assessing whether these may be more cost effective in the long run. What is lacking, and the Fourth Generation of maintenance will provide, is an integrated approach that pulls together all of the design tools and maintenance tools that exist into an integrated whole. This tool does not yet exist, and so it is not exactly clear what form that approach will take. However, it is fair to say that it will include and integrate:
While we do not know exactly what form the tool will take, we do know that all good, marketable techniques must have a TLA (a Three Letter Acronym)! Accordingly, I'll call this integrative tool Total Asset Management, or TAM for short. In the area of Information technology, we already see many equipment items being designed to provide alarms or shutdown in the event of impending failure. Examples include lifts in commercial buildings, which automatically telephone the service centre whenever it detects an impending equipment failure. Diesel locomotives, which have complex on-board computer systems which monitors equipment performance and provides both diagnostic information and notifies the operator when maintenance attention will be required. This trend will continue and expand, but in the Fourth Generation of Maintenance we will see this information being integrated into Computerised Maintenance Management systems. Trends will be able to be monitored and alarm levels adjusted accordingly, following RCM principles. Already in the United States there are mine sites where the performance of engines in large haul trucks is monitored in real-time, and transmitted via radio to Information systems and computer terminals sitting on Maintenance planners desks. In many cases, the Maintenance planner is aware of an impending problem on a truck engine before the operator. Similar opportunities will appear in the areas of fixed plant. CONCLUSIONThe Fourth Generation of Maintenance will provide the capability to achieve another step change improvement in equipment performance. The key to achieving these gains, however, will be that organisations will need to have firmly established themselves in the Third Generation of maintenance. RCM principles will be at the heart of the Fourth generation of maintenance, and those organisations that have not yet fully embraced RCM principles, and have not integrated these principles into "the way we do maintenance around here" will not be in a position to make the next step to the Fourth Generation. In our experience, most organisations are still struggling to come to grips with the Second Generation of Maintenance, and are only just starting to venture into the Third Generation, so perhaps this discussion of the Fourth Generation of Maintenance is premature. But when it arrives, the prize will be great.
|