Introduction to Reliability Centered Maintenance (RCM)
|
| Plant Maintenance Resource Center
Introduction to Reliability Centered Maintenance (RCM)
| |
|
|
|
|
Introduction to Reliability-centered MaintenanceThis is an excerpt of the first chapter of the book "Reliability-centred Maintenance" by John Moubray. You may order this book through this website by clicking here.1.1 The Changing World of MaintenanceOver the past twenty years, maintenance has changed, perhaps more so than any other management discipline. The changes are due to a huge increase in the number and variety of physical assets (plant, equipment and buildings) which must be maintained throughout the world, much more complex designs, new maintenance techniques and changing views on maintenance organization and responsibilities.Maintenance is also responding to changing expectations. These include a rapidly growing awareness of the extent to which equipment failure affects safety and the environment, a growing awareness of the connection between maintenance and product quality, and increasing pressure to achieve high plant availability and to contain costs. The changes are testing attitudes and skills in all branches of industry to the limit. Maintenance people are having to adopt completely new ways of thinking and acting, as engineers and as managers. At the same time the limitations of maintenance systems are becoming increasingly apparent, no matter how much they are computerized. In the face of this avalanche of change, managers everywhere are looking for a new approach to maintenance. They want to avoid the false starts and dead ends which always accompany major upheavals. Instead they seek a strategic framework which synthesizes the new developments into a coherent pattern, so that they can evaluate them sensibly and apply those likely to be of most value to them and their companies. This book describes a philosophy which provides just such a frame-work. It is called Reliability-centered Maintenance, or RCM. If it is applied correctly, RCM transforms the relationships between the undertakings which use it, their existing physical assets and the people who operate and maintain those assets. It also enables new assets to be put into effective service with great speed, confidence and precision. This chapter provides a brief introduction to RCM, starting with a look at how maintenance has evolved over the past fifty years. 1.2 Reliability-centered MaintenanceSince the 1930's, the evolution of maintenance can be traced through three generations. RCM is rapidly becoming a cornerstone of the Third Generation, but this generation can only be viewed in perspective in the light of the First and Second Generations.The First Generation The First Generation covers the period up to World War II. In those days industry was not very highly mechanized, so downtime did not matter much. This meant that the prevention of equipment failure was not a very high priority in the minds of most managers. At the same time, most equipment was simple and much of it was over-designed. This made it reliable and easy to repair. As a result, there was no need for systematic maintenance of any sort beyond simple cleaning, servicing and lubrication routines. The need for skills was also lower than it is today. The Second Generation Things changed dramatically during World War II. Wartime pressures increased the demand for goods of all kinds while the supply of industrial manpower dropped sharply. This led to increased mechanization. By the 1950's machines of all types were more numerous and more complex. Industry was beginning to depend on them. As this dependence grew, downtime came into sharper focus. This led to the idea that equipment failures could and should be prevented, which led in turn to the concept of preventive maintenance. In the 1960's, this consisted mainly of equipment overhauls done at fixed intervals. The cost of maintenance also started to rise sharply relative to other operating costs. This led to the growth of maintenance planning and control systems. These have helped greatly to bring maintenance under control, and are now an established part of the practice of maintenance. Finally, the amount of capital tied up in fixed assets together with a sharp increase in the cost of that capital led people to start seeking ways in which they could maximize the life of the assets. The Third Generation Since the mid-seventies, the process of change in industry has gathered even greater momentum. The changes can be classified under the headings of new expectations, new research and new techniques.< Figure 1. 1 shows how expectations of maintenance have evolved. 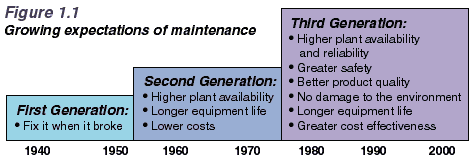 Downtime has always affected the productive capability of physical assets by reducing output, increasing operating costs and interfering with customer service. By the 1960's and 1970's, this was already a major concern in the mining, manufacturing and transport sectors. In manufacturing, the effects of downtime are being aggravated by the worldwide move towards just-in-time systems, where reduced stocks of work-in-progress mean that quite small breakdowns are now much more likely to stop a whole plant. In recent times, the growth of mechanization and automation has meant that reliability and availability have now also become key issues in sectors as diverse as health care, data processing, telecommunications and building management. Greater automation also means that more and more failures affect our ability to sustain satisfactory quality standards. This applies as much to standards of service as it does to product quality. For instance, equipment failures can affect climate control in buildings and the punctuality of transport networks as much as they can interfere with the consistent achievement of specified tolerances in manufacturing. More and more failures have serious safety or environmental consequences, at a time when standards in these areas are rising rapidly. In some parts of the world, the point is approaching where organizations either conform to society's safety and environmental expectations, or they cease to operate. This adds an order of magnitude to our dependence on the integrity of our physical assets - one which goes beyond cost and which becomes a simple matter of organizational survival. At the same time as our dependence on physical assets is growing, so too is their cost - to operate and to own. To secure the maximum return on the investment which they represent, they must be kept working efficiently for as long as we want them to. Finally, the cost of maintenance itself is still rising, in absolute terms and as a proportion of total expenditure. In some industries, it is now the second highest or even the highest element of operating costs. As a result, in only thirty years it has moved from almost nowhere to the top of the league as a cost control priority. New research Quite apart from greater expectations, new research is changing many of our most basic beliefs about age and failure. In particular, it is apparent that there is less and less connection between the operating age of most assets and how likely they are to fail. Figure 1.2 shows how the earliest view of failure was simply that as things got older, they were more likely to fail. A growing awareness of 'infant mortality' led to widespread Second Generation belief in the "bathtub" curve. 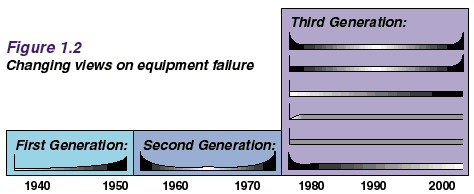 However, Third Generation research has revealed that not one or two but six failure patterns actually occur in practice. This is discussed in detail later, but it too is having a profound effect on maintenance. New techniques There has been explosive growth in new maintenance concepts and techniques. Hundreds have been developed over the past fifteen years, and more are emerging every week. Figure 1.3 shows how the classical emphasis on overhauls and administrative systems has grown to include many new developments in a number of different fields. 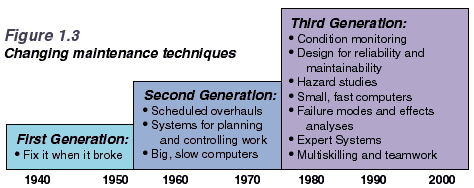 The new developments include:
A major challenge facing maintenance people nowadays is not only to learn what these techniques are, but to decide which are worthwhile and which are not in their own organizations. If we make the right choices, it is possible to improve asset performance and at the same time contain and even reduce the cost of maintenance. If we make the wrong choices, new problems are created while existing problems only get worse. The challenges facing maintenance In a nutshell, the key challenges facing modem maintenance managers can be summarized as follows:
RCM provides a framework which enables users to respond to these challenges, quickly and simply. It does so because it never loses sight of the fact that maintenance is about physical assets. If these assets did not exist, the maintenance function itself would not exist. So RCM starts with a comprehensive, zero-based review of the maintenance requirements of each, asset in its operating context. All too often, these requirements are taken for granted. This results in the development of organization structures, the deployment of resources and the implementation of systems on the basis of incomplete or incorrect assumptions about the real needs of the assets. On the other hand, if these requirements are defined correctly in the light of modem thinking, it is possible to achieve quite remarkable step changes in maintenance efficiency and effectiveness. The rest of this chapter introduces RCM in more detail. It begins by exploring the meaning of 'maintenance' itself. It goes on to define RCM and to describe the seven key steps involved in applying this process. Maintenance and RCM From the engineering viewpoint, there are two elements to the management of any physical asset. It must be maintained and from time to time it may also need to be modified. The major dictionaries define maintain as cause to continue (Oxford) or keep in an existing state (Webster). This suggests that maintenance means preserving something. On the other hand, they agree that to modify something means to change it in some way. This distinction between maintain and modify has profound implications which are discussed at length in later chapters. However, we focus on maintenance at this point. When we set out to maintain something, what is it that we wish to cause to continue? What is the existing state that we wish to preserve? The answer to these questions can be found in the fact that every physical asset is put into service because someone wants it to do something. In other words, they expect it to fulfill a specific function or functions. So it follows that when we maintain an asset, the state we wish to preserve must be one in which it continues to do whatever its users want it to do. Maintenance: Ensuring that physical assets continue to do what their users want them to do What the users want will depend on exactly where and how the asset is being used (the operating context). This leads to the following formal definition of Reliability-centered Maintenance: Reliability-centered Maintenance: a process used to determine the maintenance requirements of any physical asset in its operating contextIn the light of the earlier definition of maintenance, a fuller definition of RCM could be 'a process used to determine what must be done to ensure that any physical asset continues to do whatever its users want it to do in its present operating context. 1.3 RCM: The seven basic questionsThe RCM process entails asking seven questions about the asset or system under review, as follows:
These questions are introduced briefly in the following paragraphs, and then considered in detail in Chapters 2 to 10 of the book. Functions and Performance Standards Before it is possible to apply a process used to determine what must be done to ensure that any physical asset continues to do whatever its users want it to do in its present operating context, we need to do two things:
This is why the first step in the RCM process is to define the functions of each asset in its operating context, together with the associated desired standards of performance. What users expect assets to be able to do can be split into two categories:
The users of the assets are usually in the best position by far to know exactly what contribution each asset makes to the physical and financial well-being of the organization as a whole, so it is essential that they are involved in the RCM process from the outset. Done properly, this step alone usually takes up about a third of the time involved in an entire RCM analysis. It also usually causes the team doing the analysis to learn a remarkable amount - often a frightening amount - about how the equipment actually works. Functions are explored in more detail in Chapter 2 of the book. Functional Failures The objectives of maintenance are defined by the functions and associated performance expectations of the asset under consideration. But how does maintenance achieve these objectives? The only occurrence which is likely to stop any asset performing to the standard required by its users is some kind of failure. This suggests that maintenance achieves its objectives by adopting a suitable approach to the management of failure. However, before we can apply a suitable blend of failure management tools, we need to identify what failures can occur. The RCM process does this at two levels:
In the world of RCM, failed states are known as functional failures because they occur when an asset is unable to fulfill a function to a standard of performance which is acceptable to the user. In addition to the total inability to function, this definition encompasses partial failures, where the asset still functions but at an unacceptable level of performance (including situations where the asset cannot sustain acceptable levels of quality or accuracy). Clearly these can only be identified after the functions and performance standards of the asset have been defined. Functional failures are discussed at greater length in Chapter 3 of the book. Failure Modes As mentioned in the previous paragraph, once each functional failure has been identified, the next step is to try to identify all the events which are reasonably likely to cause each failed state. These events are known as failure modes. "Reasonably likely" failure modes include those which have occurred on the same or similar equipment operating in the same context, failures which are currently being prevented by existing maintenance regimes, and failures which have not happened yet but which are considered to be real possibilities in the context in question. Most traditional lists of failure modes incorporate failures caused by deterioration or normal wear and tear. However, the list should include failures caused by human errors (on the part of operators and maintainers) and design flaws so that all reasonably likely causes of equipment failure can be identified and dealt with appropriately. It is also important to identify the cause of each failure in enough detail to ensure that time and effort are not wasted trying to treat symptoms instead of causes. On the other hand, it is equally important to ensure that time is not wasted on the analysis itself by going into too much detail. Failure Effects The fourth step in the RCM process entails listing failure effects, which describe what happens when each failure mode occurs. These descriptions should include all the information needed to support the evaluation of the consequences of the failure, such as:
Failure modes and effects are discussed at greater length in Chapter 4 of the book. The process of identifying functions functional failures failure modes and failure effects yields surprising and often very exciting opportunities for improving performance and safety, and also for eliminating waste. Failure Consequences A detailed analysis of an average industrial undertaking is likely to yield between three and ten thousand possible failure modes. Each of these failures affects the organization in some way, but in each case, the effects are different. They may affect operations. They may also affect product quality, customer service, safety or the environment. They will all take time and cost money to repair. It is these consequences which most strongly influence the extent to which we try to prevent each failure. In other words, if a failure has serious consequences, we are likely to go to great lengths to try to avoid it. On the other hand, if it has little or no effect, then we may decide to do no routine maintenance beyond basic cleaning and lubrication. A great strength of RCM is that it recognizes that the consequences of failures are far more important than their technical characteristics. In fact, it recognizes that the only reason for doing any kind of proactive maintenance is not to avoid failures per se, but to avoid or at least to reduce the consequences of failure. The RCM process classifies these consequences into four groups, as follows:
We will see later how the RCM process uses these categories as the basis of a strategic framework for maintenance decision-making. By forcing a structured review of the consequences of each failure mode in terms of the above categories, it integrates the operational, environmental and safety objectives of the maintenance function. This helps to bring safety and the environment into the mainstream of maintenance management. The consequence evaluation process also shifts emphasis away from the idea that all failures are bad and must be prevented. In so doing, it focuses attention on the maintenance activities which have most effect on the performance of the organization, and diverts energy away from those which have little or no effect. It also encourages us to think more broadly about different ways of managing failure, rather than to concentrate only on failure prevention. Failure management techniques are divided into two categories:
The consequence evaluation process is discussed again briefly later this chapter, and in much more detail in Chapter 5 of the book. The next section of this chapter looks at proactive tasks in more detail. Proactive Tasks Many people still believe that the best way to optimize plant availability is to do some kind of proactive maintenance on a routine basis. Second Generation wisdom suggested that this should consist of overhauls of component replacements at fixed intervals. Figure 1.4 illustrates the fixed interval view of failure. 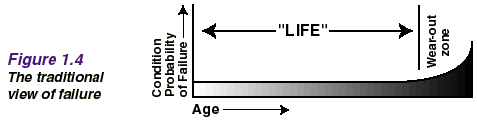 Figure 1.4 is based on the assumption that most items operate reliably for a period of time, and then wear out. Classical thinking suggests that extensive records about failure will enable us to determine this life and so make plans to take preventive action shortly before the item is due to fail in future. This model is true for certain types of simple equipment, and for some complex items with dominant failure modes. In particular, wear-out char-acteristics are often found where equipment comes into direct contact with the product. Age-related failures are also often associated with fatigue, corrosion, abrasion and evaporation. However, equipment in general is far more complex than it was twenty years ago. This has led to startling changes in the patterns of failure, as shown in Figure 1.5. The graphs show conditional probability of failure against operating age for a variety of electrical and mechanical items. 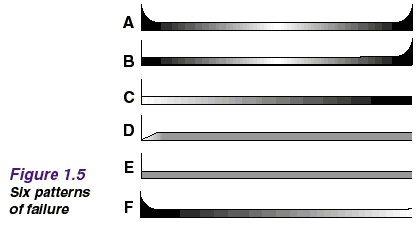 Pattern A is the well-known bathtub curve. It begins with a high incidence of failure (known as infant mortality) followed by a constant or gradually increasing conditional probability of failure, then by a wear-out zone. Pattern B shows constant or slowly increasing conditional prob-ability of failure, ending in a wear-out zone (the same as Figure 1.4). Pattern C shows slowly increasing conditional probability of failure, but there is no identifiable wear-out age. Pattern D shows low conditional probability of failure when the item is new or just out of the shop, then a rapid increase to a constant level, while pattern E shows a constant conditional probability of failure at all ages (random failure). Pattern F starts with high infant mortality, which drops eventually to a constant or very slowly increasing conditional probability of failure. Studies done on civil aircraft showed that 4% of the items conformed to pattern A, 2% to B, 5% to C, 7% to D, 14% to E and no fewer than 68% to pattern F. (The number of times these patterns occur in aircraft is not necessarily the same as in industry. But there is no doubt that as assets become more complex, we see more and more of patterns E and F.) These findings contradict the belief that there is always a connection between reliability and operating age. This belief led to the idea that the more often an item is overhauled, the less likely it is to fail. Nowadays, this is seldom true. Unless there is a dominant age-related failure mode, age limits do little or nothing to improve the reliability of complex items. In fact scheduled overhauls can actually increase overall failure rates by introducing infant mortality into otherwise stable systems. An awareness of these facts has led some organizations to abandon the idea of proactive maintenance altogether. In fact, this can be the right thing to do for failures with minor consequences. But when the failure consequences are significant, something must be done to prevent or predict the failures, or at least to reduce the consequences. This brings us back to the question of proactive tasks. As mentioned earlier, RCM divides proactive tasks into three categories, as follows:
Scheduled restoration and scheduled discard tasks Scheduled restoration entails remanufacturing a component or overhauling an assembly at or before a specified age limit, regardless of its condition at the time. Similarly, scheduled discard entails discarding an item at or before a specified life limit, regardless of its condition at the time. Collectively, these two types of tasks are now generally known as preventive maintenance. They used to be by far the most widely used form of proactive maintenance. However for the reasons discussed above, they are much less widely used than they were twenty years ago. On-condition tasks The continuing need to prevent certain types of failure, and the growing inability of classical techniques to do so, are behind the growth of new types of failure management. The majority of these techniques rely on the fact that most failures give some warning of the fact that they are about to occur. These warnings are known as potential failures, and are defined as identifiable physical conditions which indicate that a functional failure is about to occur or is in the process of occurring. The new techniques are used to detect potential failures so that action can be taken to avoid the consequences which could occur if they degenerate into functional failures. They are called on-condition tasks because items are left in service on the condition that they continue to meet desired performance standards. (On-condition maintenance includes predictive maintenance, condition-based maintenance and condition monitoring.) Used appropriately, on-condition tasks are a very good way of managing failures, but they can also be an expensive waste of time. RCM enables decisions in this area to be made with particular confidence. Default Actions RCM recognizes three major categories of default actions, as follows:
The RCM Task Selection Process A great strength of RCM is the way it provides simple, precise and easily understood criteria for deciding which (if any) of the proactive tasks is technically feasible in any context, and if so for deciding how often they should be done and who should do them. These criteria are discussed in more detail in Chapters 6 and 7 of the book. Whether or not a proactive task is technically feasible is governed by the technical characteristics of the task and of the failure which it is meant to prevent. Whether it is worth doing is governed by how well it deals with the consequences of the failure. If a proactive task cannot be found which is both technically feasible and worth doing, then suitable default action must be taken. The essence of the task selection process is as follows:
This approach means that proactive tasks are only specified for failures which really need them, which in turn leads to substantial reductions in routine workloads. This routine work also means that the remaining tasks are more I likely to be done properly. This together with the elimination of counterproductive tasks leads to more effective maintenance. Compare this with the traditional approach to the development of maintenance policies.
|

